Motivation¶
He et al. start from the observation that 20-layer models out performed 56-layer models on image classification tasks at that time (Fig. 2).
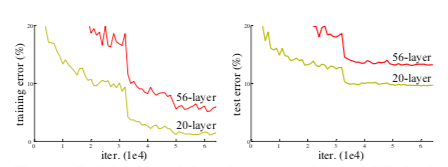
- Figure 2. Training error (left) and test error (right) on CIFAR-10 with 20-layer and 56-layer “plain” networks.
Why doesn't the 56-layer model perform at least as well? For example, couldn't the first 20-layers be identical to the smaller model, then the remaining layers just need to output their input. In linear algebra the function that outputs its input is the identity function.
He et al. hypothesised that latter layers in the 56-layer model have a detrimental effect on performance because they struggle to learn how to pass their input through with only fine-grained adjustment. Then they asked, how might we make it easier for convolutional layers to model small changes?
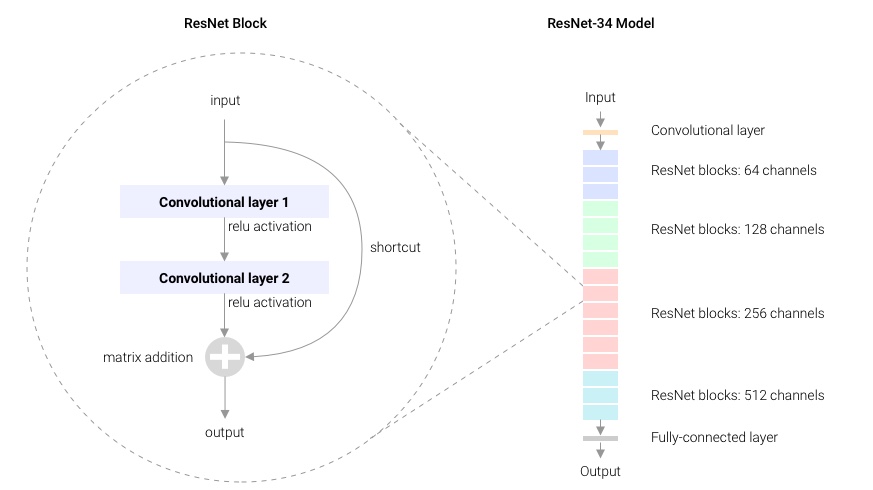
The ResNet solution is to provide a shortcut connection from the input of a layer to its output. The example illustrated in Fig 1. shows a shortcut across two layers.
With a shortcut connection the layer learns the difference, or the residual, between input and output.
$$z = x + f(x) $$
A simple change but this now means that if the optimal solution is to model the identity function then the layer learns to output a zero matrix for all inputs e.g. $f(x) = 0$. The assumption being that it is easier for a convolutional layer to learn $f(x)$ that returns zero, than it is to learn $f(x)$ that returns $x$. In the authors' words:
"We hypothesize that it is easier to optimize the residual mapping than to optimize the original, unreferenced mapping. To the extreme, if an identity mapping were optimal, it would be easier to push the residual to zero than to fit an identity mapping by a stack of nonlinear layers." - He et al. 2015
Why would it be any easier for a layer to learn a function that maps to zero than it is to learn the identity function? Let's take a closer look.
A minimal example¶
Consider a minimal example, a single convolutional layer that outputs an array of the same shape as its input with kernel size 3, stride 1, padding 1. Our input is a tiny 3x3 grayscale image with a single channel. Assume that the objective is to perform the identity mapping.
With a residual shortcut in place the layer's objective is to output a matrix of zeros irrespective of input. If every weight in the kernel is zero, then every input will be multiplied by zero and so the output must be zero in every position.
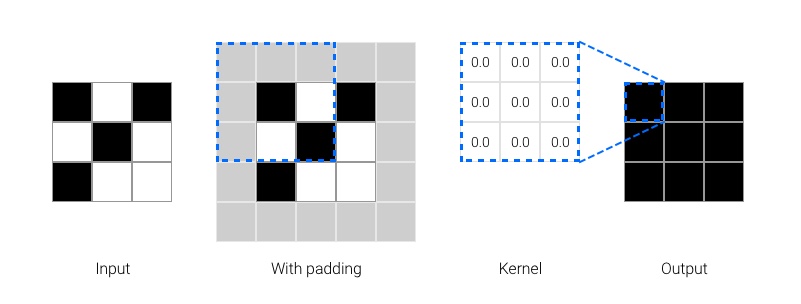
- Figure 3. Optimal parameters for a 3x3, stride 1 convolution that maps any input to zero.
Next let's consider the weights needed to perform an identity mapping. In this case the only thing we change is to set the central kernel weight to 1.0. Intuitively the kernel selects the central pixel at each position and ignores all others.
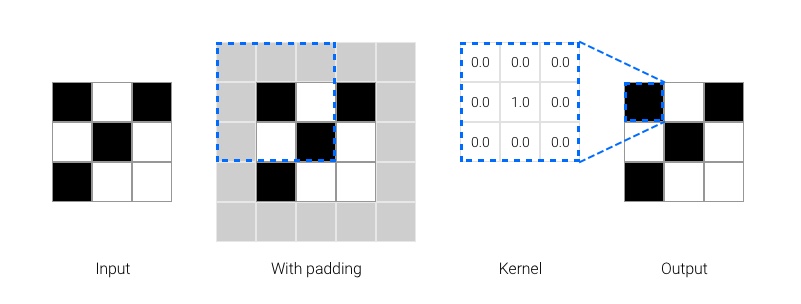
- Figure 4. Optimal parameters for a 3x3, stride 1 convolution that maps any input to the unaltered input.
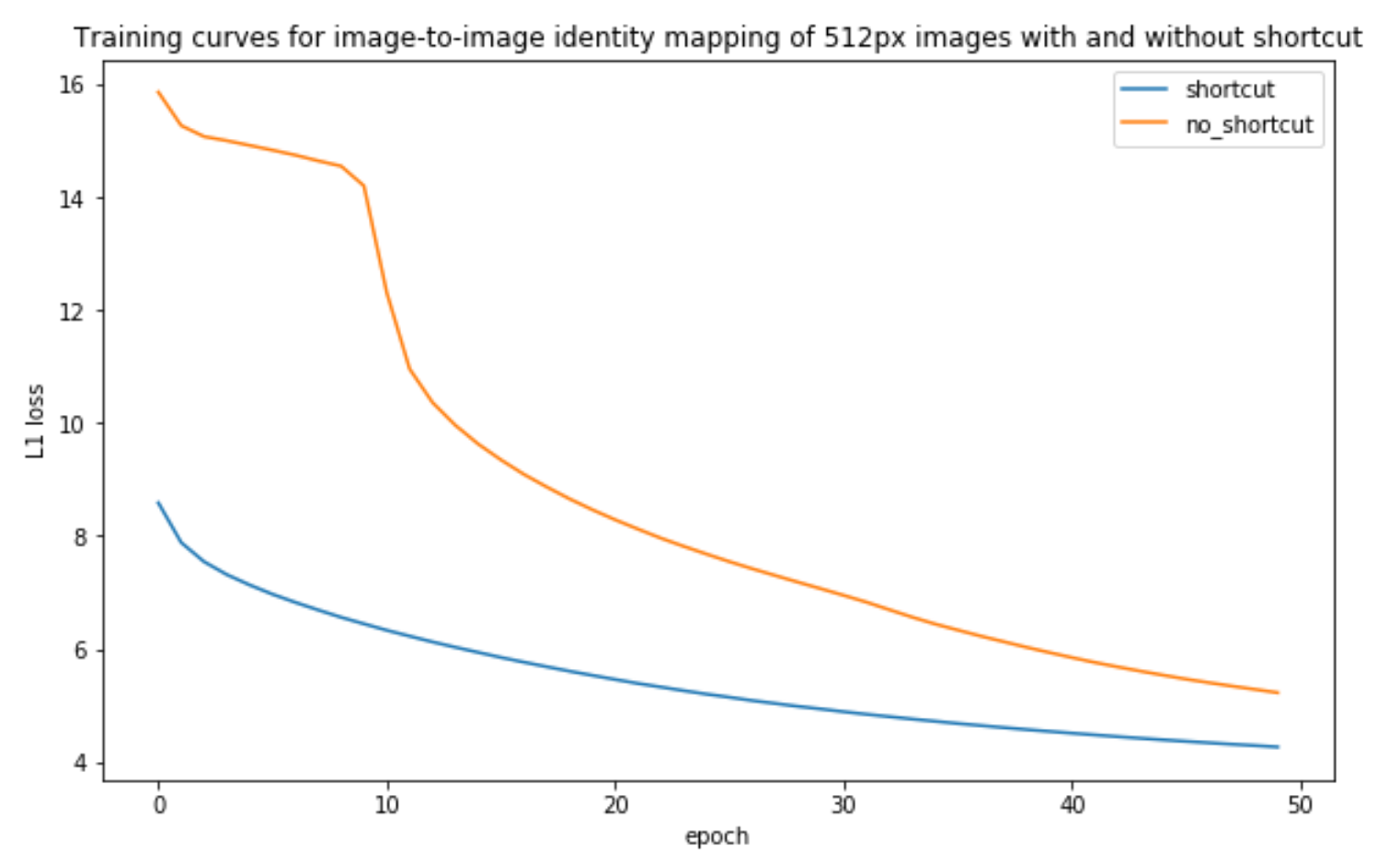
If He's hypothesis is correct we expect that learning the identity objective should be harder than learning the zero objective. It's still not obvious that this is the case but it turns out we can run a very minimal experiment to see for ourselves.